A Search Engine for Legal Documents
The following project was a collaborative effort by Asrita V Mandalam, Miloni Mittal and Simran Sehgal. We built it as a submission for the NetApp Women Innovathon 2020 and were able to win the second runners up position. To view the code click here.

The Problem
A couple of months before Covid-19 started, we were scammed by a cab company. We were charged more than the agreed upon amount. None of us knew whom to approach. Although we did manage to resolve it with a bit of hassle, it got us thinking about the prevalence of the injustice faced. Many neighbourhoods have complained about open potholes. Unfortunate strangers have faced minor robberies. Haven’t you been charged for unfair electricity bills? Maybe some of us have complained. Most haven’t. When people are unaware of the gravity of their problem, they miss out on getting the justice they deserve. Even in cases of major crime, many people across the country find it difficult to understand the jargons or access legal cases that are similar to theirs, leading to an unaware society.
To venture into how technology can increase awareness about the law and justice system in India, we have created an MVP: Just-Justice. Legal matters can be a scary place and we hope to overcome this with our solution. There are millions of documents available based on the established law and legal proceedings that have taken place in the past. These act as a reference to Lawyers, Judges and people seeking justice. Building a specialised search engine (in the form of a website) for Lawyers, Judges and people looking to file cases eases the process of searching for relevant documents.
From learning about search engines in our Information Retrieval class to building one, we know that it would not have been possible without the guidance of the team at NetApp.
Use Case
The Indian Legal System is precedence-based and new judgements are inspired from previous similar judgements. Thus, legal document retrieval becomes especially important for all parties involved in the legal process- the ordinary citizen who will file a case, the lawyer who will fight it, and the judge who will preside over it.
As our inspiration for the project was borne out of our own troubles with the Legal System, the initial versions of Just-Justice were centered around increasing the ordinary Indian citizen’s accessibility to the law. Ease of use, minimalistic design and reduction of legal jargon was prioritized.
As we dwelled deeper into the nuances of the Indian Penal Code, we observed a lot of need and scope for organisation and retrieval of documents by lawyers and judges too. Hence the further iterations of Just-Justice catered to a wider crowd, and focussed around proper management of case documents, implementing filters (such as Date, Judge, Appeal) and linking related documents together. This gave more power to people who understood the legal system, mainly Judges and Lawyers.
Motivation
There do exist platforms like that of the Supreme Court of India which help in retrieval of legal documents but they require exact details and are not open for free text queries. Websites like those of the High Court of Karnataka and High Court of Rajasthan provide for free text queries but do not help in understanding the division of various chapters/sections of the law. We aim to solve this problem by providing the user with impactful visualisations which they can make use of to understand the technicalities. Moreover, we want to encourage the use of free text search to increase the reach.
The Search Engine Implementation
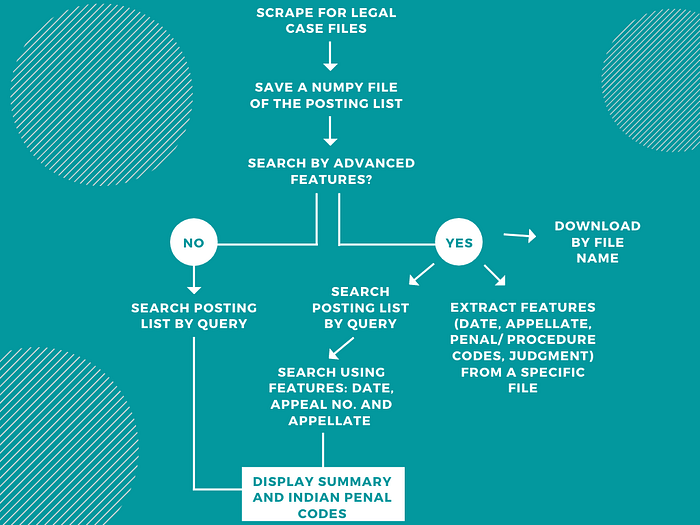
Using a Vector Space Model Based Information Retrieval System with lnc.ltc scoring, we generated the features of the dataset. They have been stored in the form of a posting list. This is then stored as a numpy file for efficient and quick retrieval of data.
Our dataset of Indian legal documents followed a defined structure. By exploiting this consistent framework, the following data was extracted:
Data
The date of the case has been provided towards the end of the first line in the format (Day Month Year). The same has been repeated in the second or third lines of the document in the format (Day/Month/Year). However, as the former appeared in every document, this format was kept in mind. We extracted the last three words of the first line of the document. Alternatively, LexNLP includes a function to extract all the dates in a document. By selecting the first date, we would arrive at the same data. However, after attempting to download LexNLP on a few systems, with two out of three failing, we decided to choose the safer and more straightforward option.
Citation
In India, reporters publish decisions made by courts. There are many reporters and they each have their own citation style. The citation line in documents consists of these. A common reporter noticed was the All India Reporter (AIR), mentioning the year of judgment, and the page number of the report in the volume. As these details were collected into a line succeeding the keyword ‘CITATION’, the line starting with the same was returned from a list of lines extracted from the document.
Appellate Jurisdiction
The appellate jurisdiction can be a Civil or Criminal jurisdiction. Not every document had this section. Those that did had the format :
CIVIL/CRIMINAL APPELLATE JURISDICTION : Civil/Criminal Appeal No. (number) of (year).
Using regular expressions, we searched for the term ‘APPELLATE JURISDICTION’, found out what type it was and retrieved the Appeal number as well.
Appeal Dismissed/Allowed
This function searches through the last paragraph to find out if the appeal was allowed or dismissed. As one of the last few sentences mentions the required information in natural language, this function starts reading from the last sentence, looks for a mention of the appeal and proceeds to search for one of the key terms: ‘allowed’ or ‘dismissed’.
Final Judgement
Most users would prefer to read the last few lines of a case file in order to understand the closing remarks made and conclusion of the case. This function retrieves the last few lines for that purpose. By splitting the document into lines, this function chooses the last few lines from the list.
Penal and Procedure Codes
This group of functions retrieves the types of Penal and Procedure Codes present in the document and the section numbers. There are three types that have been retrieved — Indian Penal Code, Criminal Procedure Code and Civil Procedure Code. The sections of the Indian Penal Code have been divided into chapters and the same can be retrieved using the function retrieve_penalCodes().
Summaries
To allow users to have a simple glimpse of the case they would like to download from the retrieved list, we have included a summariser. It uses cosine similarity to retrieve the most relevant summary of the document.
Now, all of these details are useful but not always to the same people. The figure gives our take on which functions could be used for each use case.
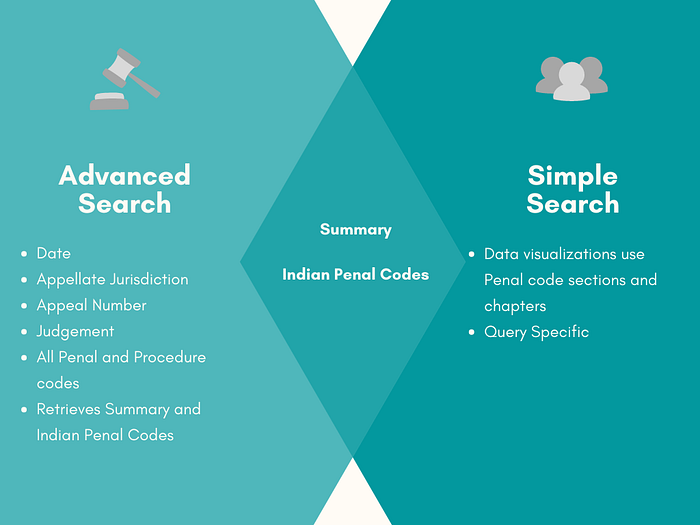
The Advanced Search feature is used mainly by Lawyers and Judges who are looking for specific cases. The Simple Search feature is used by the common man who needs data about a specific query. The following chart shows the various steps each type of search takes.
Data Visualizations
Data visualizations are easy-to-digest data nuggets which convey context at a glance. The aim of designing data visualizations for Just-Justice was 2 fold- to reduce the legal jargon and add colour to the world of law, and to make a visual method for cataloging documents and finding related pieces.
For our website, we created 3 data visualisations by firstly deciding the context, then extracting the data and finally charting the visualisation. The context was decided by prioritizing the use cases, the data was extracted by writing python scripts, and the charting was done by using Flourish and publishing an HTML embedding for the website.
India Map
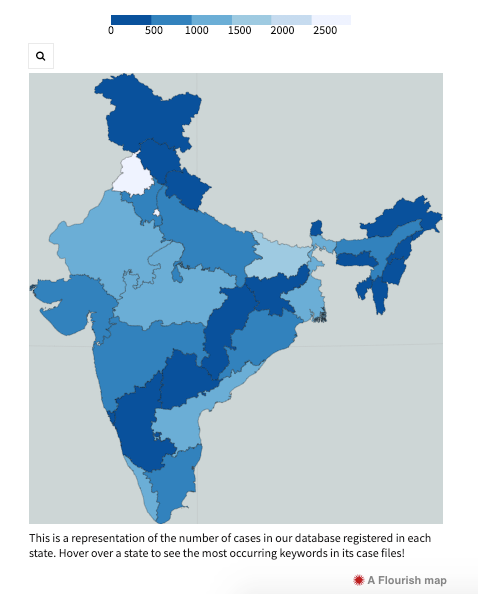
Context: For our homepage, we wanted a simplistic viz that conveyed the diversity of India and the Legal System. We wanted to demonstrate how states differ in their legal habits, what kind of cases are filed in each state, whether our prejudices of North, South, East, West are based in some truth.
Data Extraction: Wrote a python script to tokenize and lemmatize the case documents and get the top word roots by frequency (after adjusting for the effect of stop words like a, the, for). The case documents were also catalogued by State by analysing the opening lines of each document which stated the court the proceedings were taking place in. After this processing, state-wise documents were binned together to get top words occurring in case documents per state and the state’s legal habits were deduced.
Visualisation: As this viz was supposed to go on our homepage, we thought the Indian Map would catch everyone’s attention. The Indian map was colorized in a graded manner by states, where a darker state meant more cases were filed. On hovering over a state, a popup defined the top words occurring in the case documents and ranged from property to divorce to art.
Network Graph
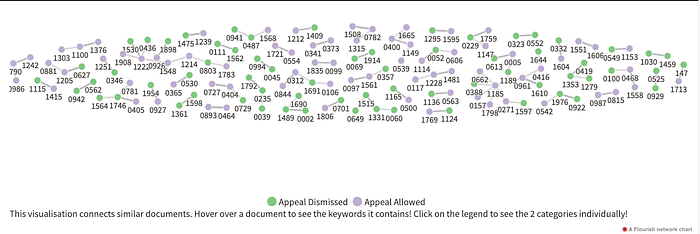
Context: For our advanced search page, we wanted a graph to represent the full dataset corpus at a glance. As the advanced search page was mainly going to be used by Lawyers and Judges, we wanted to give them easy accessibility into our case documents and find related documents quickly.
Data Extraction: The processing and extraction was similar to the previous viz. Each case document was represented by the top 3 highest occurring key words. Pairwise similarity of documents was measured by converting them into tf-idf vectors and computing the cosine similarity. A heuristic threshold was decided above which the documents were considered similar and related.
Visualization: To scope out our whole dataset and show the relationships between individual case documents, we chose a network graph. Each document is represented as a colored dot and is connected to similar documents. Upon hovering over a document, you can find the top keywords present in it. A further level of granularity was added by coloring the dots purple and green if the appeal was dismissed or allowed. After realising the whole visualization, it was easy to see clusters of documents form according to common keywords present in them.
Tree Map
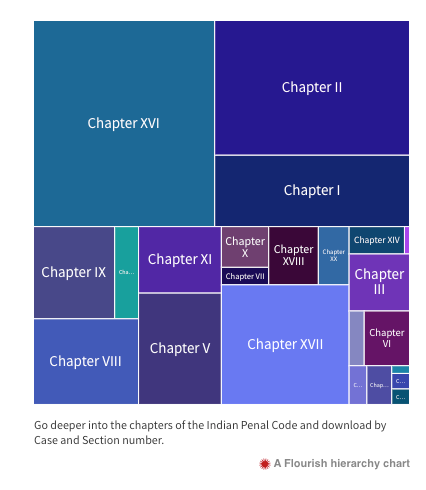
Context: A crucial piece of a retrieval system is suggesting more files that the user would be interested in after a search. We wanted to make this feature more engaging and that set the context for the next visualization. After analysing some searches and reading up more on the Indian legal system, we realised that most queries return a bunch of case documents belonging to the same Indian Penal Code. This is because the IPC is organised in chapters and sections and is a great catalogue already!
Data Extraction: To harness the cataloguing power of IPCs, we used the same filtering code we had used for our website to extract IPCs of each case document. A case document might have more than 1 IPC and all of them were extracted per case document.
Visualization: The IPC has 23 chapters that span over 511 sections. To demonstrate this multi-level hierarchical structure, we chose a tree map that goes deeper into chapters, and then goes deeper into the sections. The tree map flowed along with the search result page which demonstrates the title of the case document, the IPCs, and a rough summary. A quick analysis of the search results page shows the IPC that is springing up the most in the results and the user can navigate to that particular IPC in the tree map and download case documents easily by clicking there!
Note: Our data visualizations were created from a limited dataset, and do not convey official information. They are only meant to represent trends.
Building the User Interface
Thought behind the User Interface
We wanted to build a simple user interface that caters to both the use cases efficiently. At the same time, we wanted to incorporate effective visualisations that help the user to obtain a general idea easily.
For Lawyers and Judges, our aim was to build an advanced search feature that uses the jargons that are used by them. Here, we wanted to implement a filter capability that they can use to easily obtain documents that they are specifically looking for.
For the general citizens, we wanted to build a simple search feature which enables them to carry out searches without the hassle of using jargons. We also wanted to provide them an option to search for cases with similar legalities.
Wireframes
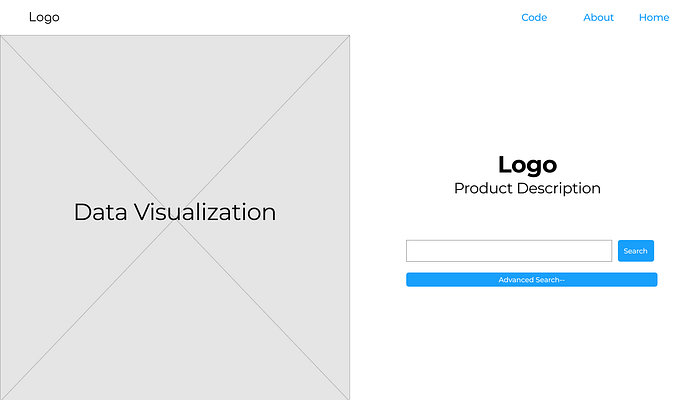
Our first step was to build a wireframe to test the UI that we have in mind. After multiple iterations, we finalised on the this UI as it provided exit points from the home page for both kinds of users.


Final User Interface




Tools Used

We used Python for the information retriever, Flask to build the APIs, HTML/CSS for the frontend and Figma for the wireframing.
Future Work
This was our experience of building an MVP for the final hackathon presentation. In the future, we would like to source more cases to form a strong dataset for retrieval. Some ideas for the same are incorporating an OCR module to get offline case documents (which form a majority of our preserved past cases) into the system, collaborate with legal institutions and private offices and establish a pipeline with the current supreme court website. Once enough users are on board, there could be features showing recent and popular activity, like a tickr tape of trending cases for faster access.
Let us know your thoughts, feedback and questions in the comments. What do you think would be good features to add in the future versions?
